[A-00173] Dataflowで色々作ってみる。
google cloudのdataflowで色々なアプリを作ってみたいと思います。
・PubSub Topicからデータ受信してGCSにファイルを作成する(Java)
googleで配布しているexampleです。
まずmavenプロジェクトを作成します。任意のフォルダにて下記のコマンドを実行します。
mvn archetype:generate -DarchetypeArtifactId=maven-archetype-quickstart -DinteractiveMode=false -DgroupId=dataflowtest -DartifactId=dataflowtest上記を適当なIDE(ここではVSCodeを使用してます)でプロジェクトを開きます。
pom.xmlを下記のように書き換えます。
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>dataflowtest</groupId>
<artifactId>dataflowtest</artifactId>
<packaging>jar</packaging>
<version>1.0-SNAPSHOT</version>
<name>dataflowtest</name>
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<beam.version>2.52.0</beam.version>
<maven-compiler-plugin.version>3.11.0</maven-compiler-plugin.version>
<maven-exec-plugin.version>3.1.1</maven-exec-plugin.version>
<maven-jar-plugin.version>3.3.0</maven-jar-plugin.version>
<maven-shade-plugin.version>3.5.1</maven-shade-plugin.version>
<slf4j.version>2.0.9</slf4j.version>
</properties>
<repositories>
<repository>
<id>apache.snapshots</id>
<name>Apache Development Snapshot Repository</name>
<url>https://repository.apache.org/content/repositories/snapshots/</url>
<releases>
<enabled>false</enabled>
</releases>
<snapshots>
<enabled>true</enabled>
</snapshots>
</repository>
<repository>
<id>confluent</id>
<url>https://packages.confluent.io/maven/</url>
</repository>
</repositories>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>${maven-compiler-plugin.version}</version>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<version>${maven-jar-plugin.version}</version>
<configuration>
<archive>
<manifest>
<addClasspath>true</addClasspath>
<classpathPrefix>lib/</classpathPrefix>
<mainClass>com.examples.pubsub.streaming.PubSubToGCS</mainClass>
</manifest>
</archive>
</configuration>
</plugin>
<!--
Configures `mvn package` to produce a bundled jar ("fat jar") for runners
that require this for job submission to a cluster.
-->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>${maven-shade-plugin.version}</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<finalName>${project.artifactId}-bundled-${project.version}</finalName>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/LICENSE</exclude>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer"/>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
<pluginManagement>
<plugins>
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>exec-maven-plugin</artifactId>
<version>${maven-exec-plugin.version}</version>
<configuration>
<cleanupDaemonThreads>false</cleanupDaemonThreads>
</configuration>
</plugin>
</plugins>
</pluginManagement>
</build>
<dependencies>
<dependency>
<groupId>org.apache.beam</groupId>
<artifactId>beam-sdks-java-core</artifactId>
<version>${beam.version}</version>
</dependency>
<!--
By default, the starter project has a dependency on the Beam DirectRunner
to enable development and testing of pipelines. To run on another of the
Beam runners, add its module to this pom.xml according to the
runner-specific setup instructions on the Beam website:
http://beam.apache.org/documentation/#runners
-->
<dependency>
<groupId>org.apache.beam</groupId>
<artifactId>beam-runners-direct-java</artifactId>
<version>${beam.version}</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.apache.beam</groupId>
<artifactId>beam-runners-google-cloud-dataflow-java</artifactId>
<version>${beam.version}</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.apache.beam</groupId>
<artifactId>beam-sdks-java-io-google-cloud-platform</artifactId>
<version>${beam.version}</version>
</dependency>
<dependency>
<groupId>org.apache.beam</groupId>
<artifactId>beam-examples-java</artifactId>
<version>${beam.version}</version>
</dependency>
<!-- slf4j API frontend binding with JUL backend -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>${slf4j.version}</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-jdk14</artifactId>
<version>${slf4j.version}</version>
</dependency>
</dependencies>
</project>
上記を作成後、mvnコマンドでclean installを実行します。
mvn clean install -DskipTests=true次にDataflowのエントリーポイントとなるクラスを作成します。
package dataflowtest;
import org.apache.beam.examples.common.WriteOneFilePerWindow;
import org.apache.beam.sdk.Pipeline;
import org.apache.beam.sdk.io.gcp.pubsub.PubsubIO;
import org.apache.beam.sdk.options.Default;
import org.apache.beam.sdk.options.PipelineOptionsFactory;
import org.apache.beam.sdk.options.StreamingOptions;
import org.apache.beam.sdk.options.Validation.Required;
import org.apache.beam.sdk.transforms.windowing.FixedWindows;
import org.apache.beam.sdk.transforms.windowing.Window;
import org.joda.time.Duration;
public class PubSubToGcs {
public interface PubSubToGcsOptions extends StreamingOptions {
@Required
String getInputTopic();
void setInputTopic(String value);
@Default.Integer(1)
Integer getWindowSize();
void setWindowSize(Integer value);
@Required
String getOutput();
void setOutput(String value);
}
public static void main(String[] args) {
int numShards = 1;
PubSubToGcsOptions options =
PipelineOptionsFactory.fromArgs(args).withValidation().as(PubSubToGcsOptions.class);
options.setStreaming(true);
Pipeline pipeline = Pipeline.create(options);
pipeline
.apply("Read PubSub Messages", PubsubIO.readStrings().fromTopic(options.getInputTopic()))
.apply(Window.into(FixedWindows.of(Duration.standardMinutes(options.getWindowSize()))))
.apply("Write Files to GCS", new WriteOneFilePerWindow(options.getOutput(), numShards));
pipeline.run().waitUntilFinish();
}
}
上記を作成したら再度mvn clean installを実行します。
次にgcloudコマンドで利用するGCPプロジェクトのAPIを有効にします。
gcloud services enable dataflow.googleapis.com compute.googleapis.com logging.googleapis.com storage-component.googleapis.com storage-api.googleapis.com pubsub.googleapis.com cloudresourcemanager.googleapis.com cloudscheduler.googleapis.com次にDataflowを実行するサービスアカウントを作成します。
gcloud iam service-accounts create dataflowtester1次にサービスアカウントにロールを付与します。
gcloud projects add-iam-policy-binding projectid --member="serviceAccount:dataflowtester1@projectid.iam.gserviceaccount.com" --role=roles/dataflow.worker
gcloud projects add-iam-policy-binding projectid --member="serviceAccount:dataflowtester1@projectid.iam.gserviceaccount.com" --role=roles/storage.objectAdmin
gcloud projects add-iam-policy-binding projectid --member="serviceAccount:dataflowtester1@projectid.iam.gserviceaccount.com" --role=roles/pubsub.admin
次にユーザーアカウント(自分のGMAILアカウント)に権限を付与します。
gcloud iam service-accounts add-iam-policy-binding dataflowtester1@projectid.iam.gserviceaccount.com --member="user:youraddress@gmail.com" --role=roles/iam.serviceAccountUser
次に各変数を宣言します。
export BUCKET_NAME=dataflow20240101bkt
export PROJECT_ID=$(gcloud config get-value project)
export TOPIC_ID=dataflow-topic
export REGION=asia-northeast1
export SERVICE_ACCOUNT=dataflowtester1@projectid.iam.gserviceaccount.com次にgsutilでGCSバケットを作成します。なるべく課金を抑えるため、ロケーションなどを指定しています。
gsutil mb -c standard -l asia-northeast1 gs://$BUCKET_NAME次にPub/Sub Topicを作成します。
gcloud pubsub topics create $TOPIC_ID最後にMavenコマンドでDataflowジョブをデプロイします。
mvn compile exec:java \
-Dexec.mainClass=dataflowtest.PubSubToGcs \
-Dexec.cleanupDaemonThreads=false \
-Dexec.args=" \
--jobName=dftest \
--project=$PROJECT_ID \
--region=asia-northeast1 \
--workerZone=asia-northeast1-a \
--workerMachineType=e2-medium \
--inputTopic=projects/$PROJECT_ID/topics/$TOPIC_ID \
--output=gs://$BUCKET_NAME/samples/output \
--gcpTempLocation=gs://$BUCKET_NAME/temp \
--runner=DataflowRunner \
--windowSize=2 \
--serviceAccount=$SERVICE_ACCOUNT"上記を実行すると下記の画面の通り、データフロージョブが作成されます。
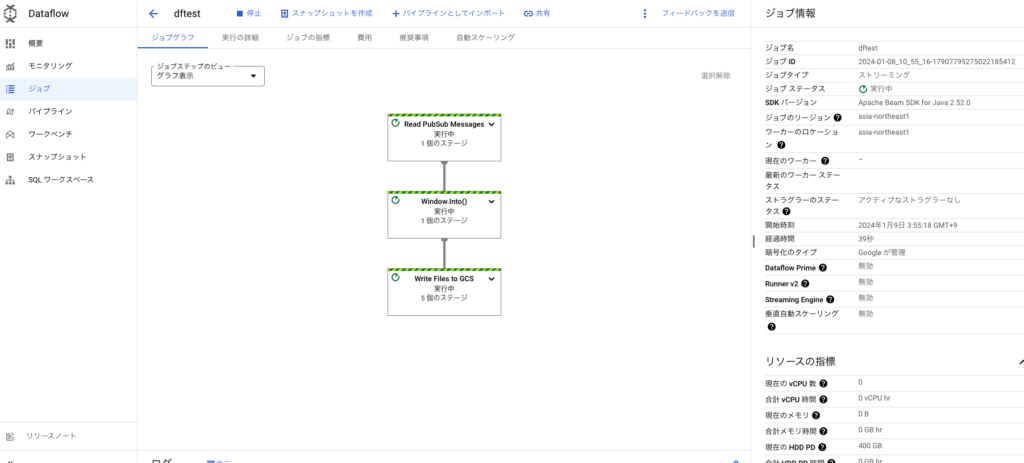
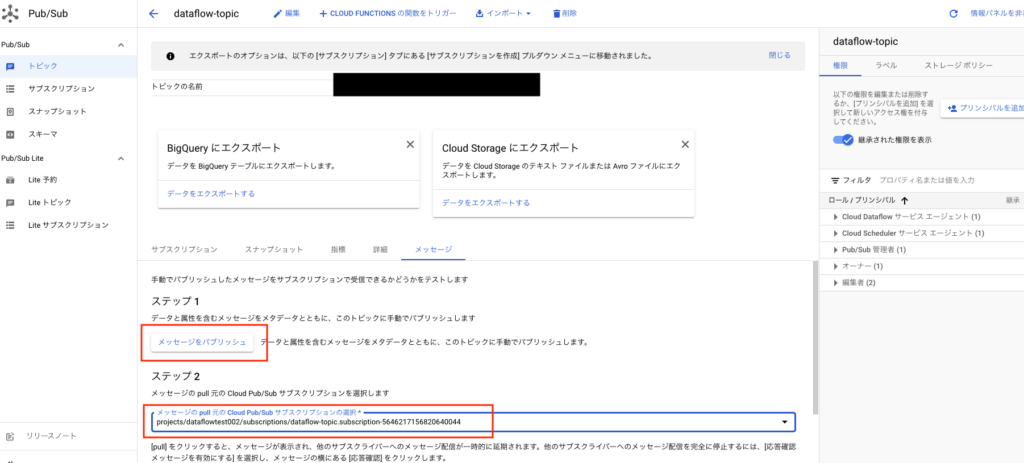
先ほど作成したPubSubトピックにメッセージをパブリッシュします。
下記の画面キャプチャを参考に適当にメッセージをパブリッシュしてください。
赤枠のサブスクリプションを指定して、パプリッシュボタンを押下します。
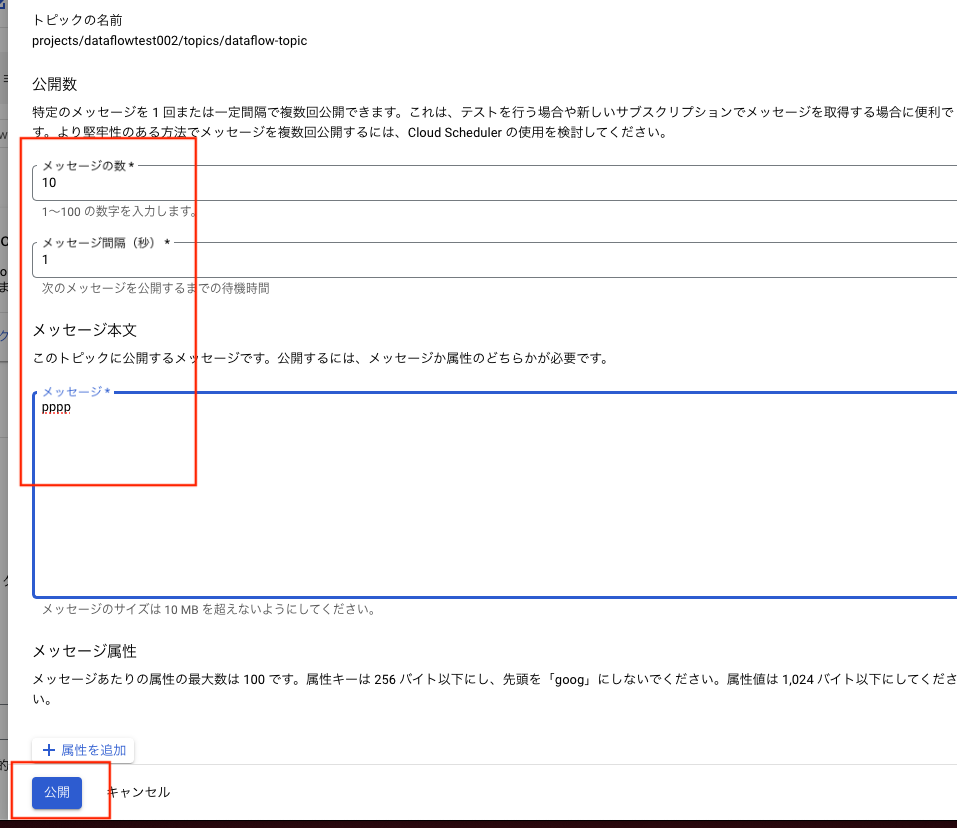
お好みのメッセージ発行数と頻度、内容を決めて公開ボタンを押下
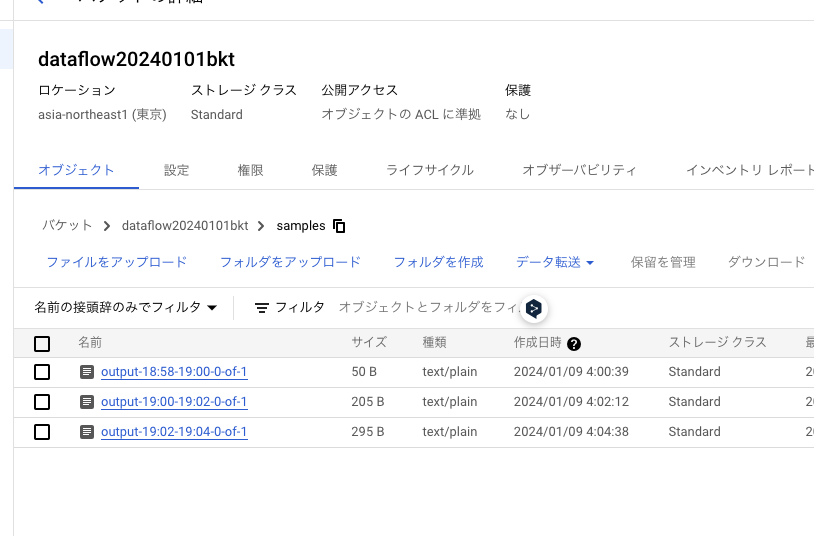
上記を実行し、5分くらいすると下記の通りGCSバケットにファイルが作成されます。
中身を確認すると先ほど発行したメッセージが記載されています。
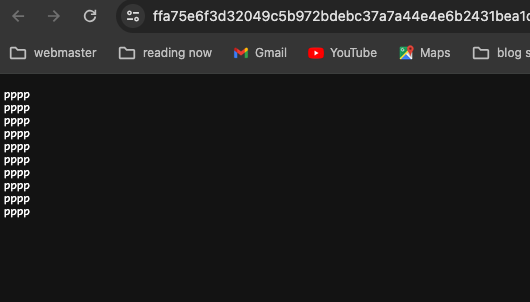
上記を確認できたらdemoは完了です。dataflowはGCEを使用しているので放置しておくと莫大な請求が来るので不要な時はすぐに止めます。Mavenを実行したターミナルでCtrl+Cで止めて、念の為、画面でも停止ボタンを押せば止まります。GCSバケットも削除しておいてください。
・PubSubストリーミングからGCSの指定バケットにデータを書き込む
タイトルの通りです。WindowSizeは2, Shardingは5にしてます。ファイル書き込み用のバケットを作成し、実行してください。
package dataflowtest;
import java.io.IOException;
import org.apache.beam.sdk.Pipeline;
import org.apache.beam.sdk.io.Compression;
import org.apache.beam.sdk.io.TextIO;
import org.apache.beam.sdk.io.gcp.pubsub.PubsubIO;
import org.apache.beam.sdk.options.Default;
import org.apache.beam.sdk.options.Description;
import org.apache.beam.sdk.options.PipelineOptionsFactory;
import org.apache.beam.sdk.options.StreamingOptions;
import org.apache.beam.sdk.options.Validation.Required;
import org.apache.beam.sdk.transforms.windowing.FixedWindows;
import org.apache.beam.sdk.transforms.windowing.Window;
import org.joda.time.Duration;
public class PubSubToGcs {
public interface PubSubToGcsOptions extends StreamingOptions {
@Description("The Cloud Pub/Sub topic to read from.")
@Required
String getInputTopic();
void setInputTopic(String value);
@Description("The Cloud Storage bucket to write to")
@Required
String getBucketName();
void setBucketName(String value);
@Description("Output file's window size in number of minutes.")
@Default.Integer(1)
Integer getWindowSize();
void setWindowSize(Integer value);
@Description("Path of the output file including its filename prefix.")
@Required
String getOutput();
void setOutput(String value);
}
public static void main(String[] args) throws IOException {
PubSubToGcsOptions options = PipelineOptionsFactory.fromArgs(args).withValidation()
.as(PubSubToGcsOptions.class);
options.setStreaming(true);
Pipeline pipeline = Pipeline.create(options);
TextIO.Write write = TextIO.write().withWindowedWrites().to(options.getBucketName()).withCompression(Compression.GZIP).withNumShards(5);
pipeline
// 1) Read string messages from a Pub/Sub topic.
.apply("Read PubSub Messages", PubsubIO.readStrings().fromTopic(options.getInputTopic()))
// 2) Group the messages into fixed-sized minute intervals.
.apply(Window.into(FixedWindows.of(Duration.standardMinutes(options.getWindowSize()))))
// 3) Write one file to GCS for every window of messages.
.apply("Write Files to GCS", write);
// Execute the pipeline and wait until it finishes running.
pipeline.run();
}
}
実行用シェルは下記になります。
#!/bin/bash
gsutil mb -c standard -l asia-northeast1 gs://jp20240120dftestbkt
mvn compile exec:java \
-Dexec.mainClass=dataflowtest.PubSubToGcs \
-Dexec.cleanupDaemonThreads=false \
-Dexec.args=" \
--jobName=dftest \
--project=$PROJECT_ID \
--region=asia-northeast1 \
--workerZone=asia-northeast1-a \
--workerMachineType=e2-medium \
--inputTopic=projects/$PROJECT_ID/topics/$TOPIC_ID \
--output=gs://$BUCKET_NAME/samples/output \
--gcpTempLocation=gs://$BUCKET_NAME/temp \
--runner=DataflowRunner \
--windowSize=2 \
--serviceAccount=$SERVICE_ACCOUNT \
--bucketName=gs://jp20240120dftestbkt"・CSVデータの特定の列のみ抽出するジョブ
CSVデータの特定の値のみ抽出するジョブです。参考文献より参考にしました。
package dataflowtest.pipeline;
import java.io.IOException;
import org.apache.beam.sdk.Pipeline;
import org.apache.beam.sdk.io.Compression;
import org.apache.beam.sdk.io.TextIO;
import org.apache.beam.sdk.io.gcp.pubsub.PubsubIO;
import org.apache.beam.sdk.options.Default;
import org.apache.beam.sdk.options.Description;
import org.apache.beam.sdk.options.PipelineOptionsFactory;
import org.apache.beam.sdk.options.StreamingOptions;
import org.apache.beam.sdk.options.Validation.Required;
import org.apache.beam.sdk.transforms.DoFn;
import org.apache.beam.sdk.transforms.ParDo;
import org.apache.beam.sdk.transforms.DoFn.ProcessElement;
import org.apache.beam.sdk.transforms.windowing.FixedWindows;
import org.apache.beam.sdk.transforms.windowing.Window;
import org.joda.time.Duration;
public class FilteringPipeline {
/**
* Options
*/
public interface FilteringPipelineOptions extends StreamingOptions {
@Description("The Cloud Pub/Sub topic to read from.")
@Required
String getInputTopic();
void setInputTopic(String value);
@Description("The Cloud Storage bucket to write to")
@Required
String getBucketName();
void setBucketName(String value);
@Description("Output file's window size in number of minutes.")
@Default.Integer(1)
Integer getWindowSize();
void setWindowSize(Integer value);
@Description("Path of the output file including its filename prefix.")
@Required
String getOutput();
void setOutput(String value);
}
/**
* Filter Class
*/
public static class DataFilter extends DoFn<String, String> {
@ProcessElement
public void process(ProcessContext c) {
String row = c.element();
String[] cells = row.split(",");
c.output(cells[4]);
}
}
public static void main(String[] args) throws IOException {
FilteringPipelineOptions options = PipelineOptionsFactory.fromArgs(args).withValidation()
.as(FilteringPipelineOptions.class);
options.setStreaming(true);
Pipeline pipeline = Pipeline.create(options);
PubsubIO.Read<String> read = PubsubIO.readStrings().fromTopic(options.getInputTopic());
Window<String> window = Window.<String>into(FixedWindows.of(Duration.standardMinutes(options.getWindowSize())));
TextIO.Write write = TextIO.write().withWindowedWrites().to(options.getBucketName())
.withCompression(Compression.GZIP).withNumShards(5);
pipeline
// 1) Read string messages from a Pub/Sub topic.
.apply("Read PubSub Messages", read)
// 2) Group the messages into fixed-sized minute intervals.
.apply(window)
// 3) Filtering Data
.apply(ParDo.of(new DataFilter()))
// 4) Write one file to GCS for every window of messages.
.apply("Write Files to GCS", write);
// Execute the pipeline and wait until it finishes running.
pipeline.run();
}
}
デプロイコマンドは下記です。
mvn compile exec:java \
-Dexec.mainClass=dataflowtest.pipeline.FilteringPipeline \
-Dexec.cleanupDaemonThreads=false \
-Dexec.args=" \
--jobName=dftest1 \
--project=$PROJECT_ID \
--region=asia-northeast1 \
--workerZone=asia-northeast1-a \
--workerMachineType=e2-medium \
--inputTopic=projects/$PROJECT_ID/topics/$TOPIC_ID \
--output=gs://$BUCKET_NAME/samples/output \
--gcpTempLocation=gs://$BUCKET_NAME/temp \
--runner=DataflowRunner \
--windowSize=2 \
--serviceAccount=$SERVICE_ACCOUNT \
--bucketName=gs://jp20240120dftestbkt"
下記のデータをPubSub Topicにパブリッシュします。
BTC/JPY,bitflyer,1519845742363,1127470.0,1126176.0・XMLのみGCSに書き込むFilterパイプライン
PubSub Topicからいろんな形式のデータが流れ込んでくることを想定してます。
この時、XMLデータのみ書き出しして、他の形式は空白行にします。
package dataflowtest.pipeline;
import java.io.IOException;
import java.io.StringReader;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import org.apache.beam.sdk.Pipeline;
import org.apache.beam.sdk.io.Compression;
import org.apache.beam.sdk.io.TextIO;
import org.apache.beam.sdk.io.gcp.pubsub.PubsubIO;
import org.apache.beam.sdk.options.Default;
import org.apache.beam.sdk.options.Description;
import org.apache.beam.sdk.options.PipelineOptionsFactory;
import org.apache.beam.sdk.options.StreamingOptions;
import org.apache.beam.sdk.options.Validation.Required;
import org.apache.beam.sdk.transforms.DoFn;
import org.apache.beam.sdk.transforms.ParDo;
import org.apache.beam.sdk.transforms.DoFn.ProcessElement;
import org.apache.beam.sdk.transforms.windowing.FixedWindows;
import org.apache.beam.sdk.transforms.windowing.Window;
import org.apache.commons.lang3.StringUtils;
import org.joda.time.Duration;
import org.w3c.dom.Document;
import org.xml.sax.InputSource;
public class FilteringPipeline2 {
/**
* Options
*/
public interface FilteringPipelineOptions extends StreamingOptions {
@Description("The Cloud Pub/Sub topic to read from.")
@Required
String getInputTopic();
void setInputTopic(String value);
@Description("The Cloud Storage bucket to write to")
@Required
String getBucketName();
void setBucketName(String value);
@Description("Output file's window size in number of minutes.")
@Default.Integer(1)
Integer getWindowSize();
void setWindowSize(Integer value);
@Description("Path of the output file including its filename prefix.")
@Required
String getOutput();
void setOutput(String value);
}
public static void main(String[] args) throws Exception {
FilteringPipelineOptions options = PipelineOptionsFactory.fromArgs(args).withValidation()
.as(FilteringPipelineOptions.class);
options.setStreaming(true);
Pipeline pipeline = Pipeline.create(options);
PubsubIO.Read<String> read = PubsubIO.readStrings().fromTopic(options.getInputTopic());
Window<String> window = Window.<String>into(FixedWindows.of(Duration.standardMinutes(options.getWindowSize())));
TextIO.Write write = TextIO.write().withWindowedWrites().to(options.getBucketName())
.withCompression(Compression.GZIP).withNumShards(5);
pipeline
// 1) Read string messages from a Pub/Sub topic.
.apply("Read PubSub Messages", read)
// 2) Group the messages into fixed-sized minute intervals.
.apply(window)
// 3) Filtering Data
.apply(ParDo.of(
new DoFn<String,String>() {
@ProcessElement
public void processElement(ProcessContext c) {
String word = c.element();
try {
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
InputSource is = new InputSource(new StringReader(word));
Document doc = builder.parse(is);
} catch (Exception e) {
c.output(StringUtils.EMPTY);
}
c.output(word);
}
}
))
// 4) Write one file to GCS for every window of messages.
.apply("Write Files to GCS", write);
// Execute the pipeline and wait until it finishes running.
pipeline.run();
}
}
mvn compile exec:java \
-Dexec.mainClass=dataflowtest.pipeline.FilteringPipeline2 \
-Dexec.cleanupDaemonThreads=false \
-Dexec.args=" \
--jobName=dftest1 \
--project=$PROJECT_ID \
--region=asia-northeast1 \
--workerZone=asia-northeast1-a \
--workerMachineType=e2-medium \
--inputTopic=projects/$PROJECT_ID/topics/$TOPIC_ID \
--output=gs://$BUCKET_NAME/samples/output \
--gcpTempLocation=gs://$BUCKET_NAME/temp \
--runner=DataflowRunner \
--windowSize=2 \
--serviceAccount=$SERVICE_ACCOUNT \
--bucketName=gs://jp20240120dftestbkt"下記のデータを交互に流してください。
{
"name": "Morpheush",
"job": "Leader",
"id": "199",
"createdAt": "2020-02-20T11:00:28.107Z"
}<?xml version="1.0" encoding="UTF-8" ?><ProgramingList><Language id="001" name="Java">Javaは標準的なプログラミング言語です</Language><Language id="002" name="Python">Pythonは標準的なプログラミング言語です</Language></ProgramingList>・並列に出力処理するパイプライン
概要:2つのバケットに対してそれぞれ一つのインプットデータを出力する単純な並列処理パイプラインです。
package dataflowtest.pipeline;
import org.apache.beam.sdk.Pipeline;
import org.apache.beam.sdk.io.TextIO;
import org.apache.beam.sdk.io.gcp.pubsub.PubsubIO;
import org.apache.beam.sdk.options.Default;
import org.apache.beam.sdk.options.Description;
import org.apache.beam.sdk.options.PipelineOptionsFactory;
import org.apache.beam.sdk.options.StreamingOptions;
import org.apache.beam.sdk.options.Validation.Required;
import org.apache.beam.sdk.transforms.windowing.FixedWindows;
import org.apache.beam.sdk.transforms.windowing.Window;
import org.apache.beam.sdk.values.PCollection;
import org.joda.time.Duration;
public class ParallelProcessPipeline {
/**
* Options
*/
public interface ParallelPipelineOptions extends StreamingOptions {
@Description("The Cloud Pub/Sub topic to read from.")
@Required
String getInputTopic();
void setInputTopic(String value);
@Description("The Cloud Storage bucket of Main to write to")
@Required
String getBucketMain();
void setBucketMain(String value);
@Description("The Cloud Storage bucket of Sub to write to")
@Required
String getBucketSub();
void setBucketSub(String value);
@Description("Output file's window size in number of minutes.")
@Default.Integer(1)
Integer getWindowSizeMain();
void setWindowSizeMain(Integer value);
@Description("Output file's window size in num or min.")
@Default.Integer(1)
Integer getWindowSizeSub();
void setWindowSizeSub(Integer value);
@Description("Output files's num of sharding.")
@Default.Integer(1)
Integer getShardNumMain();
void setShardNumMain(Integer value);
@Description("Output files's num of sharding.")
@Default.Integer(1)
Integer getShardNumSub();
void setShardNumSub(Integer value);
@Description("Path of the output file including its filename prefix.")
@Required
String getOutput();
void setOutput(String value);
}
public static void main(String[] args) throws Exception {
ParallelPipelineOptions options = PipelineOptionsFactory.fromArgs(args).withValidation()
.as(ParallelPipelineOptions.class);
options.setStreaming(true);
Pipeline pipeline = Pipeline.create(options);
PubsubIO.Read<String> read = PubsubIO.readStrings().fromTopic(options.getInputTopic());
PCollection<String> readItem = pipeline.apply("Read from Topic.", read);
// Main Process
readItem.apply("Window Main",Window.into(FixedWindows.of(Duration.standardMinutes(options.getWindowSizeMain()))))
.apply("Write to main", TextIO.write().withWindowedWrites().withNumShards(options.getShardNumMain()).to(options.getBucketMain()));
//Sub Process
readItem.apply("Window Sub",Window.into(FixedWindows.of(Duration.standardMinutes(options.getWindowSizeSub()))))
.apply("Write to sub", TextIO.write().withWindowedWrites().withNumShards(options.getShardNumSub()).to(options.getBucketSub()));
// Execute the pipeline and wait until it finishes running.
pipeline.run();
}
}
出力先が2つになるのでバケットを作成します。
gsutil mb -c standard -l asia-northeast1 gs://jp20240122dftestbktsubmvn compile exec:java \
-Dexec.mainClass=dataflowtest.pipeline.ParallelProcessPipeline \
-Dexec.cleanupDaemonThreads=false \
-Dexec.args=" \
--jobName=dftest1 \
--project=$PROJECT_ID \
--region=asia-northeast1 \
--workerZone=asia-northeast1-a \
--workerMachineType=e2-medium \
--inputTopic=projects/$PROJECT_ID/topics/$TOPIC_ID \
--output=gs://$BUCKET_NAME/samples/output \
--gcpTempLocation=gs://$BUCKET_NAME/temp \
--runner=DataflowRunner \
--windowSizeMain=1 \
--windowSizeSub=2 \
--shardNumMain=3 \
--shardNumSub=5 \
--serviceAccount=$SERVICE_ACCOUNT \
--bucketMain=gs://jp20240120dftestbkt \
--bucketSub=gs://jp20240122dftestbktsub"
・並列にフィルタリング処理するパイプライン
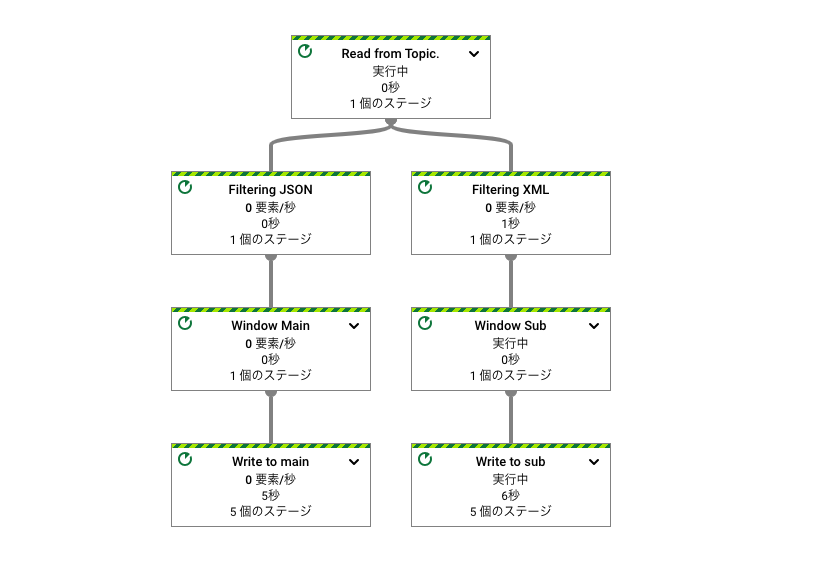
概要:pubsubからXMLとJSONデータを交互に受信し、別々のバケットにファイル保管するパイプラインです。
各パイプライン処理にてParDo,DoFnの無名関数を実装してフィルタリングします。
Dataflow図は下記です。
package dataflowtest.pipeline;
import java.io.StringReader;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import org.apache.beam.sdk.Pipeline;
import org.apache.beam.sdk.io.TextIO;
import org.apache.beam.sdk.io.gcp.pubsub.PubsubIO;
import org.apache.beam.sdk.options.Default;
import org.apache.beam.sdk.options.Description;
import org.apache.beam.sdk.options.PipelineOptionsFactory;
import org.apache.beam.sdk.options.StreamingOptions;
import org.apache.beam.sdk.options.Validation.Required;
import org.apache.beam.sdk.transforms.DoFn;
import org.apache.beam.sdk.transforms.ParDo;
import org.apache.beam.sdk.transforms.DoFn.ProcessElement;
import org.apache.beam.sdk.transforms.windowing.FixedWindows;
import org.apache.beam.sdk.transforms.windowing.Window;
import org.apache.beam.sdk.values.PCollection;
import org.joda.time.Duration;
import org.w3c.dom.Document;
import org.xml.sax.InputSource;
import com.fasterxml.jackson.databind.JsonNode;
import com.fasterxml.jackson.databind.ObjectMapper;
public class ParallelFilteringProcessPipeline {
/**
* Options
*/
public interface ParallelFilteringProcessPipelineOptions extends StreamingOptions {
@Description("The Cloud Pub/Sub topic to read from.")
@Required
String getInputTopic();
void setInputTopic(String value);
@Description("The Cloud Storage bucket of Main to write to")
@Required
String getBucketMain();
void setBucketMain(String value);
@Description("The Cloud Storage bucket of Sub to write to")
@Required
String getBucketSub();
void setBucketSub(String value);
@Description("Output file's window size in number of minutes.")
@Default.Integer(1)
Integer getWindowSizeMain();
void setWindowSizeMain(Integer value);
@Description("Output file's window size in num or min.")
@Default.Integer(1)
Integer getWindowSizeSub();
void setWindowSizeSub(Integer value);
@Description("Output files's num of sharding.")
@Default.Integer(1)
Integer getShardNumMain();
void setShardNumMain(Integer value);
@Description("Output files's num of sharding.")
@Default.Integer(1)
Integer getShardNumSub();
void setShardNumSub(Integer value);
@Description("Path of the output file including its filename prefix.")
@Required
String getOutput();
void setOutput(String value);
}
public static void main(String[] args) throws Exception {
ParallelFilteringProcessPipelineOptions options = PipelineOptionsFactory.fromArgs(args).withValidation()
.as(ParallelFilteringProcessPipelineOptions.class);
options.setStreaming(true);
Pipeline pipeline = Pipeline.create(options);
PubsubIO.Read<String> read = PubsubIO.readStrings().fromTopic(options.getInputTopic());
PCollection<String> readItem = pipeline.apply("Read from Topic.", read);
// Main Process(JSON処理用)
readItem.apply("Filtering JSON",
ParDo.of(new DoFn<String, String>() {
@ProcessElement
public void filteringJson(ProcessContext c) {
String word = c.element();
try {
ObjectMapper mapper = new ObjectMapper();
JsonNode root = mapper.readTree(word);
c.output(word);
} catch (Exception e) {
}
}
}))
.apply("Window Main",
Window.into(FixedWindows.of(Duration.standardMinutes(options.getWindowSizeMain()))))
.apply("Write to main", TextIO.write().withWindowedWrites().withNumShards(options.getShardNumMain())
.to(options.getBucketMain()));
// Sub Process(XML処理用)
readItem.apply("Filtering XML",
ParDo.of(new DoFn<String, String>() {
@ProcessElement
public void filteringXML(ProcessContext c) {
String word = c.element();
try {
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
InputSource is = new InputSource(new StringReader(word));
Document doc = builder.parse(is);
c.output(word);
} catch (Exception e) {
}
}
}))
.apply("Window Sub",
Window.into(FixedWindows.of(Duration.standardMinutes(options.getWindowSizeSub()))))
.apply("Write to sub", TextIO.write().withWindowedWrites().withNumShards(options.getShardNumSub())
.to(options.getBucketSub()));
// Execute the pipeline and wait until it finishes running.
pipeline.run();
}
}
gsutil mb -c standard -l asia-northeast1 gs://jp20240122dftestbktsub
mvn compile exec:java \
-Dexec.mainClass=dataflowtest.pipeline.ParallelFilteringProcessPipeline \
-Dexec.cleanupDaemonThreads=false \
-Dexec.args=" \
--jobName=dftest1 \
--project=$PROJECT_ID \
--region=asia-northeast1 \
--workerZone=asia-northeast1-a \
--workerMachineType=e2-medium \
--inputTopic=projects/$PROJECT_ID/topics/$TOPIC_ID \
--output=gs://$BUCKET_NAME/samples/output \
--gcpTempLocation=gs://$BUCKET_NAME/temp \
--runner=DataflowRunner \
--windowSizeMain=1 \
--windowSizeSub=1 \
--shardNumMain=3 \
--shardNumSub=3 \
--serviceAccount=$SERVICE_ACCOUNT \
--bucketMain=gs://jp20240120dftestbkt \
--bucketSub=gs://jp20240122dftestbktsub"
下記はテストデータです。
<?xml version="1.0" encoding="UTF-8" ?><ProgramingList><Language id="001" name="Java">Javaは標準的なプログラミング言語です</Language><Language id="002" name="Python">Pythonは標準的なプログラミング言語です</Language></ProgramingList>{ "name": "Morpheush", "job": "Leader", "id": "199", "createdAt": "2020-02-20T11:00:28.107Z" }・条件により分岐した処理を実行するパイプライン
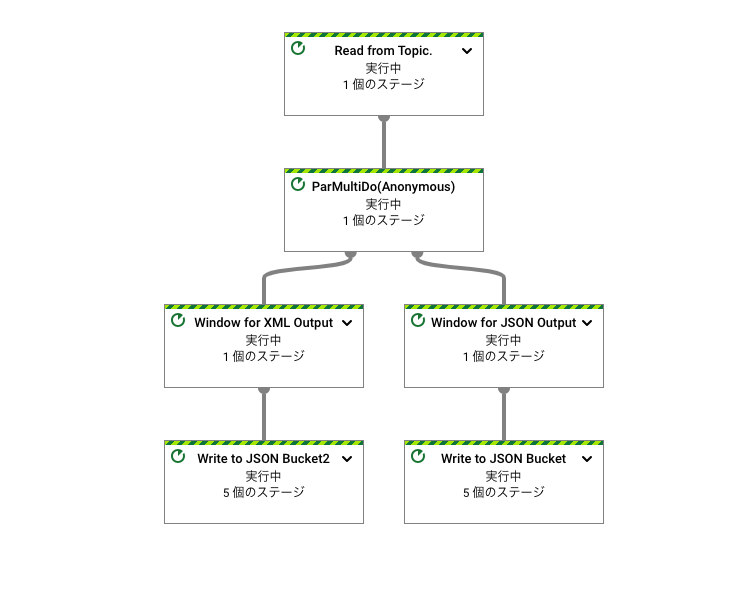
概要:並列に組んだ処理をデータ条件により流入先を切り替えるパイプラインです。TupleTagを用いてswitch処理のように切り替えて、条件に合致した処理を実行します。
Dataflow図はこちら
package dataflowtest.pipeline;
import org.apache.beam.sdk.Pipeline;
import org.apache.beam.sdk.io.TextIO;
import org.apache.beam.sdk.io.gcp.pubsub.PubsubIO;
import org.apache.beam.sdk.options.Default;
import org.apache.beam.sdk.options.Description;
import org.apache.beam.sdk.options.PipelineOptionsFactory;
import org.apache.beam.sdk.options.StreamingOptions;
import org.apache.beam.sdk.options.Validation.Required;
import org.apache.beam.sdk.transforms.DoFn;
import org.apache.beam.sdk.transforms.ParDo;
import org.apache.beam.sdk.transforms.windowing.FixedWindows;
import org.apache.beam.sdk.transforms.windowing.Window;
import org.apache.beam.sdk.values.PCollection;
import org.apache.beam.sdk.values.PCollectionTuple;
import org.apache.beam.sdk.values.TupleTag;
import org.apache.beam.sdk.values.TupleTagList;
import org.joda.time.Duration;
import com.fasterxml.jackson.databind.JsonNode;
import com.fasterxml.jackson.databind.ObjectMapper;
public class ParallelFilteringTagProcessPipeline {
/** Process Tags */
static final TupleTag<String> processJsonTag = new TupleTag<String>() {
};
static final TupleTag<String> processXmlTag = new TupleTag<String>() {
};
/**
* Options
*/
public interface ParallelFilteringTagProcessPipelineOptions extends StreamingOptions {
@Description("The Cloud Pub/Sub topic to read from.")
@Required
String getInputTopic();
void setInputTopic(String value);
@Description("The Cloud Storage bucket of Main to write to")
@Required
String getBucketMain();
void setBucketMain(String value);
@Description("The Cloud Storage bucket of Sub to write to")
@Required
String getBucketSub();
void setBucketSub(String value);
@Description("Output file's window size in number of minutes.")
@Default.Integer(1)
Integer getWindowSizeMain();
void setWindowSizeMain(Integer value);
@Description("Output file's window size in num or min.")
@Default.Integer(1)
Integer getWindowSizeSub();
void setWindowSizeSub(Integer value);
@Description("Output files's num of sharding.")
@Default.Integer(1)
Integer getShardNumMain();
void setShardNumMain(Integer value);
@Description("Output files's num of sharding.")
@Default.Integer(1)
Integer getShardNumSub();
void setShardNumSub(Integer value);
@Description("Path of the output file including its filename prefix.")
@Required
String getOutput();
void setOutput(String value);
}
public static void main(String[] args) throws Exception {
ParallelFilteringTagProcessPipelineOptions options = PipelineOptionsFactory.fromArgs(args).withValidation()
.as(ParallelFilteringTagProcessPipelineOptions.class);
options.setStreaming(true);
Pipeline pipeline = Pipeline.create(options);
PubsubIO.Read<String> read = PubsubIO.readStrings().fromTopic(options.getInputTopic());
PCollection<String> readItem = pipeline.apply("Read from Topic.", read);
PCollectionTuple tagCollection = readItem.apply(ParDo.of(new DoFn<String, String>() {
@ProcessElement
public void processElement(ProcessContext c) {
String element = c.element();
try {
ObjectMapper mapper = new ObjectMapper();
JsonNode node = mapper.readTree(element);
c.output(processJsonTag, element);
} catch (Exception e) {
c.output(processXmlTag, element);
}
}
}).withOutputTags(processJsonTag, TupleTagList.of(processXmlTag)));
// Main Process(JSON処理用)
tagCollection.get(processJsonTag)
.apply("Window for JSON Output",
Window.into(FixedWindows.of(Duration.standardMinutes(options.getWindowSizeMain()))))
.apply("Write to JSON Bucket", TextIO.write().withWindowedWrites().withNumShards(options.getShardNumMain())
.to(options.getBucketMain()));
// Sub Process(XML処理用)
tagCollection.get(processXmlTag)
.apply("Window for XML Output",
Window.into(FixedWindows.of(Duration.standardMinutes(options.getWindowSizeSub()))))
.apply("Write to XML Bucket", TextIO.write().withWindowedWrites().withNumShards(options.getShardNumSub())
.to(options.getBucketSub()));
// Execute the pipeline and wait until it finishes running.
pipeline.run();
}
}
mvn compile exec:java \
-Dexec.mainClass=dataflowtest.pipeline.ParallelFilteringTagProcessPipeline \
-Dexec.cleanupDaemonThreads=false \
-Dexec.args=" \
--jobName=dftest1 \
--project=$PROJECT_ID \
--region=asia-northeast1 \
--workerZone=asia-northeast1-a \
--workerMachineType=e2-medium \
--inputTopic=projects/$PROJECT_ID/topics/$TOPIC_ID \
--output=gs://$BUCKET_NAME/samples/output \
--gcpTempLocation=gs://$BUCKET_NAME/temp \
--runner=DataflowRunner \
--windowSizeMain=1 \
--windowSizeSub=1 \
--shardNumMain=3 \
--shardNumSub=3 \
--serviceAccount=$SERVICE_ACCOUNT \
--bucketMain=gs://jp20240120dftestbkt \
--bucketSub=gs://jp20240122dftestbktsub" 下記はテストデータです。
{ "name": "Morpheush", "job": "Leader", "id": "199", "createdAt": "2020-02-20T11:00:28.107Z" }<?xml version="1.0" encoding="UTF-8" ?><ProgramingList><Language id="001" name="Java">Javaは標準的なプログラミング言語です</Language><Language id="002" name="Python">Pythonは標準的なプログラミング言語です</Language></ProgramingList>・ファイルネームをカスタマイズする
独自のファイルネームポリシーを作成して自分の好きなファイル名にするコードです。
package dataflowtest.pipeline;
import java.io.IOException;
import org.apache.beam.sdk.Pipeline;
import org.apache.beam.sdk.io.FileSystems;
import org.apache.beam.sdk.io.TextIO;
import org.apache.beam.sdk.io.fs.ResourceId;
import org.apache.beam.sdk.io.gcp.pubsub.PubsubIO;
import org.apache.beam.sdk.options.Default;
import org.apache.beam.sdk.options.Description;
import org.apache.beam.sdk.options.PipelineOptionsFactory;
import org.apache.beam.sdk.options.StreamingOptions;
import org.apache.beam.sdk.options.Validation.Required;
import org.apache.beam.sdk.transforms.windowing.FixedWindows;
import org.apache.beam.sdk.transforms.windowing.Window;
import org.joda.time.Duration;
import dataflowtest.policy.CustomFileNamePolicy;
public class CustomFilenamePipeline {
public interface PubSubToGcsMPOptions extends StreamingOptions {
@Description("The Cloud Pub/Sub topic to read from.")
@Required
String getInputTopic();
void setInputTopic(String value);
@Description("The Cloud Storage bucket to write to")
@Required
String getBucketName();
void setBucketName(String value);
@Description("Output file's window size in number of minutes.")
@Default.Integer(1)
Integer getWindowSize();
void setWindowSize(Integer value);
@Description("Path of the output file including its filename prefix.")
@Required
String getOutput();
void setOutput(String value);
}
public static void main(String[] args) throws IOException {
PubSubToGcsMPOptions options = PipelineOptionsFactory.fromArgs(args).withValidation()
.as(PubSubToGcsMPOptions.class);
options.setStreaming(true);
Pipeline pipeline = Pipeline.create(options);
String gcsPath = new StringBuilder().append("gs://").append(options.getBucketName()).append("/").toString();
CustomFileNamePolicy policy = new CustomFileNamePolicy(gcsPath);
ResourceId resourceId = FileSystems.matchNewResource(gcsPath, true);
PubsubIO.Read<String> read = PubsubIO.readStrings().fromTopic(options.getInputTopic());
Window<String> window = Window.<String>into(FixedWindows.of(Duration.standardMinutes(options.getWindowSize())));
TextIO.Write write = TextIO.write().to(policy)
.withTempDirectory(resourceId.getCurrentDirectory())
.withWindowedWrites().withNumShards(5);
pipeline
// 1) Read string messages from a Pub/Sub topic.
.apply("Read PubSub Messages", read)
// 2) Group the messages into fixed-sized minute intervals.
.apply(window)
// 3) Write one file to GCS for every window of messages.
.apply("Write Files to GCS", write);
// Execute the pipeline and wait until it finishes running.
pipeline.run();
}
}
下記のクラスはpolicyディレクトリを作成して格納してください。
package dataflowtest.policy;
import org.apache.beam.repackaged.core.org.apache.commons.lang3.StringUtils;
import org.apache.beam.sdk.io.FileSystems;
import org.apache.beam.sdk.io.FileBasedSink.FilenamePolicy;
import org.apache.beam.sdk.io.FileBasedSink.OutputFileHints;
import org.apache.beam.sdk.io.fs.ResourceId;
import org.apache.beam.sdk.io.fs.ResolveOptions.StandardResolveOptions;
import org.apache.beam.sdk.transforms.windowing.BoundedWindow;
import org.apache.beam.sdk.transforms.windowing.IntervalWindow;
import org.apache.beam.sdk.transforms.windowing.PaneInfo;
import org.joda.time.DateTimeZone;
import org.joda.time.format.DateTimeFormatter;
import org.joda.time.format.ISODateTimeFormat;
public class CustomFileNamePolicy extends FilenamePolicy {
private static final DateTimeFormatter dateFormatter = ISODateTimeFormat.basicDate().withZone(DateTimeZone.getDefault());
private static final DateTimeFormatter hourFormatter = ISODateTimeFormat.hourMinute();
private final ResourceId baseFilename;
public CustomFileNamePolicy(String baseFilename) {
this.baseFilename = FileSystems.matchNewResource(baseFilename, true);
}
public String filenamePrefixForWindow(IntervalWindow window) {
//String filePrefix = baseFilename.isDirectory() ? "" : firstNonNull(baseFilename.getFilename(), "");
String directoryName = dateFormatter.print(window.start());
return String.format("%s/HKK_RAW_DATA_%s",directoryName, dateFormatter.print(window.start()) + StringUtils.remove(hourFormatter.print(window.start()), ':') );
}
@Override
public ResourceId windowedFilename(int shardNumber, int numShards, BoundedWindow window,PaneInfo paneInfo,
OutputFileHints outputFileHints) {
IntervalWindow intervalWindow = (IntervalWindow) window;
String filename = String.format("%s_%s.jsonl",
filenamePrefixForWindow(intervalWindow),
shardNumber+1,
numShards);
return baseFilename.getCurrentDirectory().resolve(filename, StandardResolveOptions.RESOLVE_FILE);
}
@Override
public ResourceId unwindowedFilename(int shardNumber, int numShards, OutputFileHints outputFileHints) {
throw new UnsupportedOperationException("Unsupported.");
}
}
実行コマンドは下記となります。
mvn compile exec:java \
-Dexec.mainClass=dataflowtest.pipeline.CustomFilenamePipeline \
-Dexec.cleanupDaemonThreads=false \
-Dexec.args=" \
--jobName=dftest \
--project=$PROJECT_ID \
--region=asia-northeast1 \
--workerZone=asia-northeast1-a \
--workerMachineType=e2-medium \
--inputTopic=projects/$PROJECT_ID/topics/$TOPIC_ID \
--output=gs://$BUCKET_NAME/samples/output \
--gcpTempLocation=gs://$BUCKET_NAME/temp \
--runner=DataflowRunner \
--windowSize=2 \
--serviceAccount=$SERVICE_ACCOUNT \
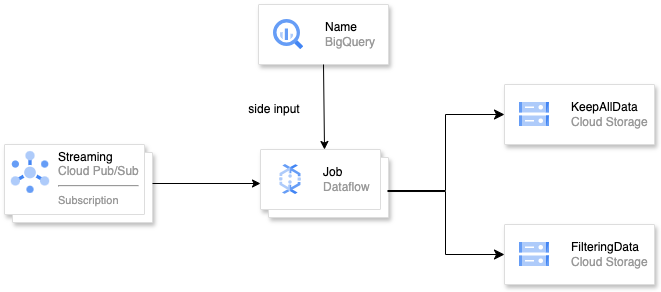
--bucketName=jp20240120dftestbkt"・条件によりフィルタリングするジョブ
下記がアーキテクチャ図になります。
・Appendix
公式ドキュメントはこちら
https://cloud.google.com/dataflow/docs/guides/templates/provided/pubsub-topic-to-text?hl=ja
https://cloud.google.com/pubsub/docs/stream-messages-dataflow?hl=ja
https://cloud.google.com/dataflow/docs/guides/setting-pipeline-options?hl=ja
https://cloud.google.com/dataflow/docs/quickstarts/create-pipeline-java?hl=ja
https://cloud.google.com/dataflow/docs/guides/develop-and-test-pipelines?hl=ja
https://cloud.google.com/compute/docs/general-purpose-machines?hl=ja#e2_machine_types
https://beam.apache.org/documentation/programming-guide/
https://beam.apache.org/documentation/transforms/java/elementwise/pardo/
https://cloud.google.com/dataflow/docs/guides/logging?hl=ja
https://beam.apache.org/documentation/programming-guide/
https://beam.apache.org/documentation/transforms/java/other/flatten/
https://cloud.google.com/dataflow/docs/guides/write-to-cloud-storage?hl=ja
参考サイトはこちら
https://qiita.com/malt03/items/26571eeccf850815c6ac
https://stackoverflow.com/questions/71832880/apache-beam-split-to-multiple-pipeline-output
https://qiita.com/Sekky0905/items/381ed27fca9a16f8ef07
https://stackoverflow.com/questions/52075600/python-apache-beam-multiple-outputs-processing
https://qiita.com/kaito__/items/91ebde6600cced74107d
https://stackoverflow.com/questions/51179443/cloud-dataflow-how-does-dataflow-do-parallelism
https://qiita.com/k_0120/items/bd79f5fadef4a04869a4
https://qiita.com/HMMNRST/items/490136dd02d6ddd7ff2e
https://qiita.com/kaito__/items/91ebde6600cced74107d
https://stackoverflow.com/questions/50930409/how-to-replace-withfilenamepolicy-in-apache-beam-2-4
https://stackoverflow.com/questions/48519834/how-to-write-to-a-file-name-defined-at-runtime
https://www.linkedin.com/pulse/apache-beam-tutorial-macrometa-corporation/
https://qiita.com/ynstkt/items/50d551f025d8612d69e1
https://qiita.com/ynstkt/items/66122643e3f48c99fa64
https://blog.jp.square-enix.com/iteng-blog/posts/00045-dataflow-stepbystep-3/
https://zenn.dev/google_cloud_jp/articles/ff268c57331b53
https://future-architect.github.io/articles/20220920a/
https://engineering.dena.com/blog/2023/12/beam-sdk-overview/
https://qiita.com/esakik/items/3c5c18d4a645db7a8634
GCPでSparkの代わりにDataflowとBeamSQLを使ってみた
Dataflowの基本的な流れ
https://www.sejuku.net/blog/80855
https://stackoverflow.com/questions/562160/in-java-how-do-i-parse-xml-as-a-string-instead-of-a-file
コメントを残す