[A-00186] Parquetデータを扱う(Java)
apache parquetデータで何ができるのかこの記事で探りたいと思います。
・Example
手始めにJavaでライブラリを使用してParquetデータを作成してみたいと思います。
下記のコマンドでmavenプロジェクトを作成します。
mvn archetype:generate \
-DarchetypeArtifactId=maven-archetype-quickstart \
-DinteractiveMode=false \
-DgroupId=example \
-DartifactId=prqettestディレクトリ構成は下記の通り
まずはpom.xmlの構成は下記の通りです。
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>example</groupId>
<artifactId>prqettest</artifactId>
<packaging>jar</packaging>
<version>1.0-SNAPSHOT</version>
<name>prqettest</name>
<url>http://maven.apache.org</url>
<properties>
<java.version>17</java.version>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
<springframework.version>3.2.4</springframework.version>
<parquet.version>1.11.0</parquet.version>
<hadoop.version>1.2.1</hadoop.version>
</properties>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
<version>${springframework.version}</version>
<!-- <exclusions>
<exclusion>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-logging</artifactId>
</exclusion>
</exclusions> -->
</dependency>
<dependency>
<groupId>org.apache.parquet</groupId>
<artifactId>parquet-hadoop</artifactId>
<version>${parquet.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-core</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.5.3</version>
</dependency>
</dependencies>
</project>次にJavaソースコードです。
package example.parquet;
import java.util.HashMap;
import java.util.List;
import org.apache.hadoop.conf.Configuration;
import org.apache.parquet.column.ColumnDescriptor;
import org.apache.parquet.hadoop.api.WriteSupport;
import org.apache.parquet.io.ParquetEncodingException;
import org.apache.parquet.io.api.Binary;
import org.apache.parquet.io.api.RecordConsumer;
import org.apache.parquet.schema.MessageType;
public class CustomWriterSupport extends WriteSupport<List<String>> {
MessageType schema;
RecordConsumer recordConsumer;
List<ColumnDescriptor> cols;
/**
* Constructor
*
* @param schema
*/
public CustomWriterSupport(MessageType schema) {
this.schema = schema;
this.cols = schema.getColumns();
}
@Override
public WriteContext init(Configuration configuration) {
return new WriteContext(schema, new HashMap<String, String>());
}
@Override
public void prepareForWrite(RecordConsumer recordConsumer) {
this.recordConsumer = recordConsumer;
}
@Override
public void write(List<String> list) {
if (list.size() != this.cols.size()) {
throw new ParquetEncodingException(
"Invalid input data. Expecting " + cols.size()
+ " columns. Input had " + list.size() + " columns ("
+ cols + ") : " + list);
}
recordConsumer.startMessage();
for (int i = 0; i < cols.size(); ++i) {
String value = list.get(i);
if (value.length() > 0) {
recordConsumer.startField(cols.get(i).getPath()[0], i);
switch (cols.get(i).getPrimitiveType().getPrimitiveTypeName()) {
case BOOLEAN:
recordConsumer.addBoolean(Boolean.parseBoolean(value));
break;
case FLOAT:
recordConsumer.addFloat(Float.parseFloat(value));
break;
case DOUBLE:
recordConsumer.addDouble(Double.parseDouble(value));
break;
case INT32:
recordConsumer.addInteger(Integer.parseInt(value));
break;
case INT64:
recordConsumer.addLong(Long.parseLong(value));
break;
case BINARY:
recordConsumer.addBinary(this.stringToBinary(value));
break;
default:
throw new ParquetEncodingException(
"Unsupported column type: " + cols.get(i).getPrimitiveType().getPrimitiveTypeName()
);
}
recordConsumer.endField(cols.get(i).getPath()[0], i);
}
}
recordConsumer.endMessage();
}
private Binary stringToBinary(Object value) {
return Binary.fromString(value.toString());
}
}
package example.parquet;
import java.io.IOException;
import java.util.List;
import org.apache.hadoop.fs.Path;
import org.apache.parquet.hadoop.ParquetWriter;
import org.apache.parquet.hadoop.metadata.CompressionCodecName;
import org.apache.parquet.schema.MessageType;
public class CustomParquetWriter extends ParquetWriter<List<String>> {
public CustomParquetWriter(
Path file,
MessageType schema,
boolean enableDictionary,
CompressionCodecName codecName
) throws IOException {
super(file, new CustomWriterSupport(schema)
, codecName
, DEFAULT_BLOCK_SIZE
, DEFAULT_PAGE_SIZE
, enableDictionary
, false);
}
}
package example;
import java.io.File;
import java.io.IOException;
import java.nio.file.Files;
import java.util.ArrayList;
import java.util.List;
import org.apache.hadoop.fs.Path;
import org.apache.parquet.hadoop.metadata.CompressionCodecName;
import org.apache.parquet.schema.MessageType;
import org.apache.parquet.schema.MessageTypeParser;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.boot.CommandLineRunner;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import example.parquet.CustomParquetWriter;
@SpringBootApplication
public class App implements CommandLineRunner {
private Logger LOGGER = LoggerFactory.getLogger(App.class);
@Value("${schema.filePath}")
private String schemaFilePath;
@Value("${output.directoryPath}")
private String outputDirectoryPath;
public static void main(String[] args) {
SpringApplication.run(App.class, args);
}
@Override
public void run(String... args) throws Exception {
LOGGER.info("Runnnig.....");
List<List<String>> columns = this.getDataForFile();
MessageType schema = getSchemaForParquet();
CustomParquetWriter writer = this.getParquetWriter(schema);
for (List<String> column : columns) {
LOGGER.info("Writing line: " + column.toArray());
writer.write(column);
}
LOGGER.info("Finished.");
writer.close();
}
private CustomParquetWriter getParquetWriter(MessageType schema) throws IOException {
String outputFilePath = outputDirectoryPath + "/" + System.currentTimeMillis() + ".parquet";
File outputParquetFile = new File(outputFilePath);
Path path = new Path(outputParquetFile.toURI().toString());
return new CustomParquetWriter(path, schema, false, CompressionCodecName.SNAPPY);
}
private MessageType getSchemaForParquet() throws IOException {
File resource = new File(this.schemaFilePath);
String rawSchema = new String(Files.readAllBytes(resource.toPath()));
return MessageTypeParser.parseMessageType(rawSchema);
}
private List<List<String>> getDataForFile() {
List<List<String>> data = new ArrayList<>();
List<String> parquetFileItem1 = new ArrayList<>();
parquetFileItem1.add("1");
parquetFileItem1.add("Name1");
parquetFileItem1.add("true");
List<String> parquetFileItem2 = new ArrayList<>();
parquetFileItem2.add("2");
parquetFileItem2.add("Name2");
parquetFileItem2.add("false");
data.add(parquetFileItem1);
data.add(parquetFileItem2);
return data;
}
}次にpropertiesファイルです。
schema.filePath=src/main/resources/schemas/user.schema
output.directoryPath=src/main/resources/outputlogback.xmlです
<configuration>
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<!-- encoders are assigned the type
ch.qos.logback.classic.encoder.PatternLayoutEncoder by default -->
<encoder>
<pattern>%d{HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</pattern>
</encoder>
</appender>
<root level="info">
<appender-ref ref="STDOUT" />
</root>
</configuration>最後にparquetデータのスキーマ定義です
message m { required INT64 id; required binary username; required boolean active; }上記を動かすと下記のようになります。
00:00:06.841 [main] INFO example.App - Starting App using Java 17.0.10 with PID 6578 (/Users/anonymous/Documents/Github/software/java/data/parquet/app1/prqettest/target/classes started by anonymous in /Users/anonymous/Documents/Github/software/java/data/parquet/app1/prqettest)
00:00:06.851 [main] INFO example.App - No active profile set, falling back to 1 default profile: "default"
00:00:08.498 [main] INFO example.App - Started App in 2.319 seconds (process running for 4.73)
00:00:08.504 [main] INFO example.App - Runnnig.....
00:00:08.804 [main] WARN o.a.hadoop.util.NativeCodeLoader - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
00:00:08.833 [main] INFO o.a.hadoop.io.compress.CodecPool - Got brand-new compressor
00:00:09.174 [main] INFO example.App - Writing line: [Ljava.lang.Object;@6ede46f6
00:00:09.176 [main] INFO example.App - Writing line: [Ljava.lang.Object;@6069dd38
00:00:09.176 [main] INFO example.App - Finished.実行後、下記のファイルが作成されます。
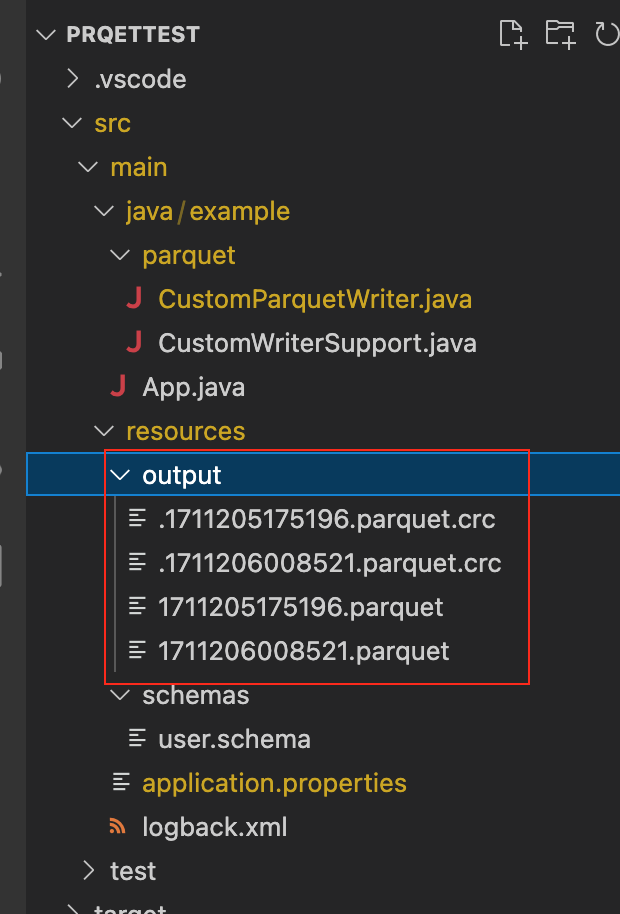
中身は下記のような感じです。
{"id":1,"username":{"0":78,"1":97,"2":109,"3":101,"4":49},"active":true}
{"id":2,"username":{"0":78,"1":97,"2":109,"3":101,"4":50},"active":false}・Appendix
公式ドキュメントはこちら
コメントを残す