[A-00213] Apache Sparkを使ってみる
apache sparkを使って色々やってみます。
・wordcountプログラムを作成する
apache sparkはすでに実行可能な状態としておきます。
詳しくは下記のURLにてダウンロード、インストールできます。
https://spark.apache.org/docs/latest/quick-start.html
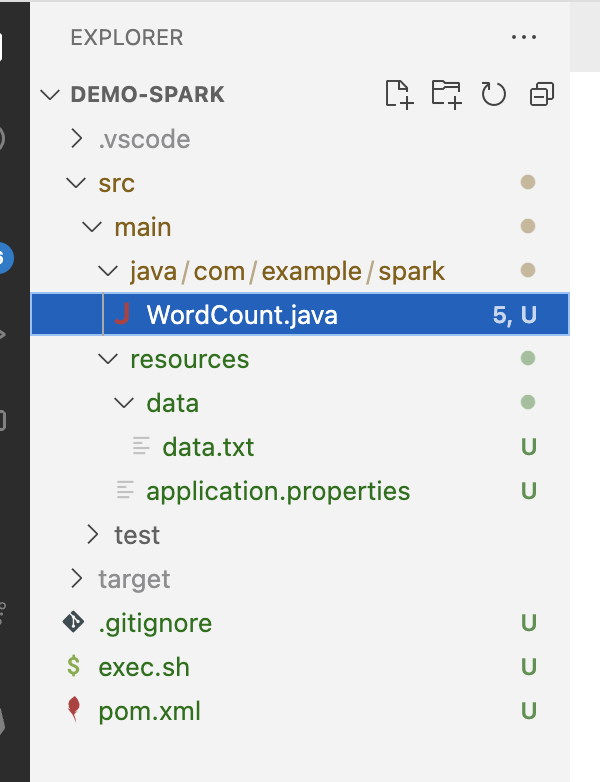
ディレクトリ構成は下記の通りです。
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.example.spark</groupId>
<artifactId>demo-spark</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>demo-spark</name>
<description>Demo project for Apache Spark</description>
<properties>
<java.version>22</java.version>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.13</artifactId>
<version>4.0.0-preview1</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.12.1</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
</goals>
</execution>
</executions>
<configuration>
<scalaVersion>2.13.14</scalaVersion>
</configuration>
</plugin>
</plugins>
</build>
</project>package com.example.spark;
import java.util.Arrays;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import scala.Tuple2;
public class WordCount {
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf().setAppName("spark-wordcount").setMaster("local");
JavaSparkContext sparkContext = new JavaSparkContext(sparkConf);
JavaRDD<String> lines = sparkContext.textFile("/Users/user/Documents/github/software/oss/apache/spark/java/apps/app1/demo-spark/src/main/resources/data/data.txt");
JavaRDD<String> words = lines.flatMap(s -> Arrays.asList(s.split(" ")).iterator());
JavaPairRDD<String, Integer> wordsOnes = words.mapToPair(s -> new Tuple2(s, 1));
JavaPairRDD<String, Integer> wordsCounts = wordsOnes.reduceByKey((v1, v2) -> v1 + v2 );
wordsCounts.saveAsTextFile("/Users/user/Documents/github/software/oss/apache/spark/java/apps/app1/demo-spark/src/main/resources/out-data");
}
}sparkで読み込むファイルを作成します。
Hi, My name is anoymous informer.
Nice to meet you.
See you again later.maven buildします。
mvn clean installtargetディレクトリ配下に作成されたjarファイルを読み込んでsparkを動かしますので適当な場所にコピーしておきます。
bash-3.2$ pwd
/Users/user/tools/spark-3.5.2-bin-hadoop3
bash-3.2$ mkdir jars
bash-3.2$ cp /Users/user/Documents/github/software/oss/apache/spark/java/apps/app1/demo-spark/target/demo-spark-0.0.1-SNAPSHOT.jar ./jars/sparkのbinディレクトリに移動し、spark-submitを実行します。
bash-3.2$ cd bin/
bash-3.2$ pwd
/Users/user/tools/spark-3.5.2-bin-hadoop3/bin
bash-3.2$ ./spark-submit --master local[3] --executor-memory 512m --class com.example.spark.WordCount ~/tools/jars/demo-spark-0.0.1-SNAPSHOT.jar上記のspark-submitを実行後、javaのプロジェクトフォルダを確認するとout-dataフォルダが作成されます。
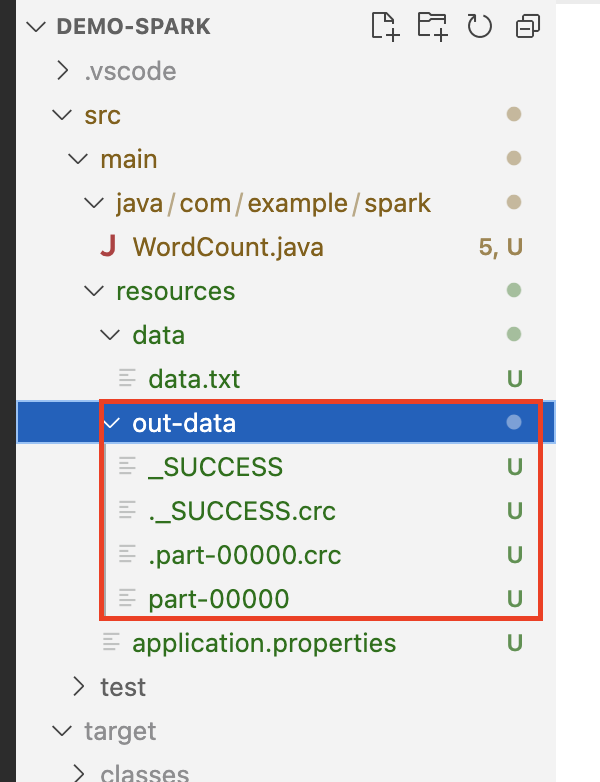
part-00000を確認するとwordの出現回数を記録した内容になっています。
(later.,1)
(is,1)
(you,1)
(anoymous,1)
(name,1)
(Nice,1)
(meet,1)
(to,1)
(Hi,,1)
(See,1)
(you.,1)
(again,1)
(My,1)
(informer.,1)・Appendix
参考文献はこちら
https://qiita.com/Hiroki11x/items/4f5129094da4c91955bc
コメントを残す